AI画像生成は意外と長くハマっています。
最近は幾つか画像投稿サイトに投稿するようになったり…
まぁ、自分の好みで作成しているだけではありますけど。
今回は、最近メインで画像生成を行っている
Windows環境にStableDiffusion及びAUTOMATIC1111を入れたときの方法
それと、
入れたときの環境で思わず大ハマりした時の内容を書いておこうと思います。

0.はじめに
基本的にはGoogleColaboratoryでやったのと同じ方法で可能です。
それもこれもAUTOMATIC1111WebUIが素晴らしい。感謝!
ローカル環境でAI画像生成が可能なようにすることで
何が嬉しいかというと、以下のような点でしょうか。
- 使用制限なし (電気代はかかる)
- 1度設定すれば2回目以降は再設定必要なし
- 容量さえ余裕があれば複数のモデルデータを保持できる
ですからね~。
イチからPCを購入するよりかは導入が簡単なのですけど
ローカル環境の便利さを覚えてしまったら、これはもう前には戻れないぜ。
1.WebUIのダウンロード
先ずはソースコードを取得します。
GoogleColaboratoryではgitコマンドで取得していました。
自分は普段使いのPCではtortoisegitを入れているので、
そのGUIからCloneしました。
2.使用するデータのダウンロード
次に使用するモデルデータのダウンロードですね。
モデルデータが配布されているホームページにアクセスして、ダウンロードします。
GoogleColaboratoryの時と同様にコマンドでダウンロードしてもいいですが、
ページから直でダウンロードしてもいいです。
画像の赤枠で括ってある下矢印の部分をクリックするとダウンロードできます。
サイズがそれなりに大きいので、ダウンロードは時間がかかります。
ここではAnything-v4.0のモデルデータを選択しました。
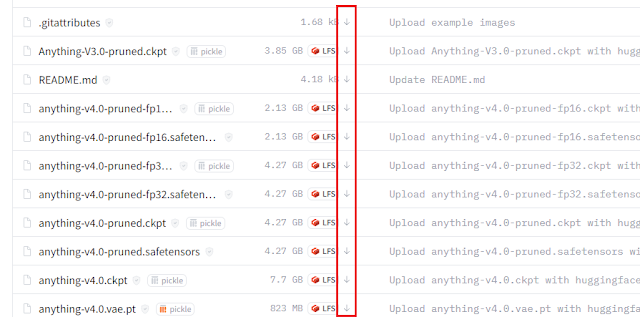
ダウンロードするデータは2種類あって、
モデルデータとVAEデータの2つがあります。
それぞれ、別のフォルダに格納する必要があります。
モデルデータは
「stable-diffusion-webui/models/Stable-diffusion」以下に、
VAEデータは
「stable-diffusion-webui/models/VAE」以下に格納します。
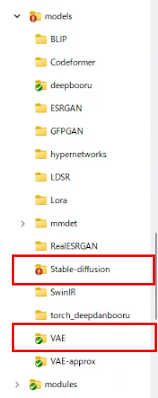
モデルデータとVAEデータを格納したら、一先ず準備完了です。
後から追加でも簡単なので、とりあえず1~2個くらい入れたら
それでいいかと思います。(適当)
3.インストール、起動
「stable-diffusion-webui」直下にある
「webui-user.bat」を実行します。

なんと基本的にこれだけ。
実行したバッチファイル内で必要なモジュールのインストールと
WebUIの起動まで自動でやってくれます。

こんなかんじで、ローカルのURL表示まで出てくれれば、大体成功です。
適当なブラウザでこのURLにアクセスすれば、
WebUIから画像生成を行うことが出来ます。

自分はここの起動で大ハマりしたのですが、
それは後程触れようと思います。
4.ちょっとした初期設定
ちょっとした初期設定として、
「webui-user.bat」のパラメータ設定と、WebUI上の設定があります。
「webui-user.bat」のパラメータ設定では、
「COMMANDLINE_ARGS」で起動するstablediffusionの設定ができます。
自分の場合は、下記のような感じにしています。
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=--precision full --no-half --medvram --xformers --deepdanbooru --enable-insecure-extension-access --autolaunch
call webui.bat
「--precision full」と「--no-half」
出力時に部分的に黒くなったり、緑になったりというのを防ぐものです。
「--medvram」
GPUメモリが中程度(4~8G)でも1024x1024等のサイズが作れるようになる
省メモリモードで動作できるオプション。
ただし動作が少し遅くなったり、作成される画像がちょっと変わるらしい?
更に低いメモリモードとして「--lowvram」もあるようです。
「--xformers」
どうもStableDiffusionを高速動作できるxformersで動かすモードの指定らしいです。
「--deepdanbooru」
WebUI上のInterrogateDeepBooruが使用できるようになるらしいです。
…が、あまり使ってないので恩恵は分かってないです!
「--autolaunch」
WebUI起動のタイミングでブラウザを起動してくれるパラメータです。
起動を待って開かなくても自動で開いてくれるので便利
自分のPCも、すごくリッチというわけではないので、
少なくともxformerとmedvramのオプションは
つけて起動してる感じですね。
次にWebUIの設定です。
「Settings>Paths for saving>Output directory...」から出力先を指定します。
デフォルトだと、起動バッチ以下の「output」ディレクトリに出力されるので、
変更したければ、ここで変更します。
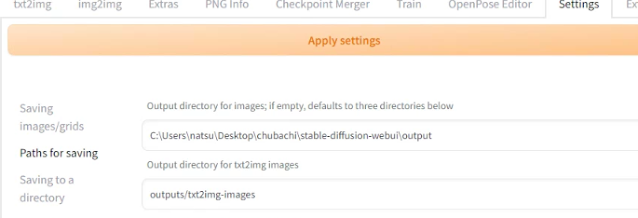
最後に、GoogleColaboratoryでもやったように
「Settings>User Interface>Quicksettings list」の項を
「sd_model_checkpoint」から
「sd_model_checkpoint,sd_vae,CLIP_stop_at_last_layers」に変更します。
こうすると、モデルデータやVAEを自由に切り替えることが出来るので便利です。

5.インストール時の大ハマりした点
主にPythonのバージョンなんですが、
既に入っているバージョンによっては起動が上手くいかないときがあります。
自分の場合ははじめPythonの3.8が入っていたのですが、
これが原因でWebUIが上手く起動できませんでした。
調べたところ、先述のxformerのインストールは
Pythonの3.10以降でないとダメなのが原因みたいです。
しかし、自分のPC内のPythonのバージョンを3.10にしても
やっぱり動かんかったのです。
んで、調べたところ、AUTOMATIC1111WebUIのバッチ起動時に
仮想環境を立ち上げていて、その中で起動しているらしく、
本体PCでPythonのバージョンをアップデートしても、
仮想環境側のPythonのバージョンが古いので、それで動かなかったようです。
だもんで、Pythonのアップデートも
仮想環境上から行う必要があったんですね。
「stable-diffusion-webui/venv/Scripts」以下に「activate」というのがあります。
これをコマンドプロンプト上から実行します。


ここからPythonの3.10をインストールすれば
起動時にxformerもインストールできるようになります。

6.おわりに
おおよそはGoogleColaboratoryでやったそのままを流用できるのですが、
一部、ローカルPC依存で発生する問題(Pythonのバージョン関連)で
思わず大ハマりしました。
しかし、この環境が出来てからは大分生成がはかどるようになりましたね!
BatchCount変更して、100枚作成するようにして放置とかできますし。
GoogleColaboratoryみたいに
毎回設定しなおしたり、ダウンロードしなおす手間もないですし。
これからの課題は…電気代と日々増えていく画像ファイルの対応かな?
そんな感じです。
ではでは。
おわりに、昨日作った画像をぺたり

0 件のコメント:
コメントを投稿