前回はWindows環境にWhisperを導入して動かすことをやっていました。
今回はGoogleColaboratoryで動かす場合の手順ですね。
これを書いていこうと思います。

GoogleColaboratoryとは?
GoogleColaboratoryはGoogleが提供してくれている、
Web上でPythonや機械学習などの環境を整えて、動かすことのできるサービスです。
Googleドライブでノートブックという形で保存して、使用することができます。
Colaboratory へようこそ
https://colab.research.google.com/?hl=ja
Colaboratoryのなにが嬉しいかって、
自動でリセットされたり、使用量の制限がついてはいるものの、
ある程度ちゃんとしたGPUがのった環境を使うことができるということ。
未だにグラフィックボードは高くて、ちょっと試したい…位では
なかなか購入するのキビしいですからね。
こうやって環境を提供してくれるのはとても嬉しい。
GoogleColaboratoryの導入
初めて使う時はGoogleドライブ内で
アプリケーションのインストールを行う必要があります。
左上にある新規作成のボタンから「その他>アプリを追加」を選んで、
表示される画面に「Google Colab」等と入力して検索すると見つけることができます。
このアプリケーションを先ずはインストールしましょう。
下の写真だと「アンインストール」と出ていますが、
初回インストール時は「インストール」と表示されるので安心してください。


GoogleColaboratory上で
Notebookを作成する
Googleドライブ内でGoogleColaboratoryをインストールすると、
新規作成から「その他>Google Colaboratory」の項目から
GoogleColaboratoryのNotebookを作成することができます。

Chromeで作成すると、別タブで下のような画面が表示されます。
作成段階では「Untitled0.ipynb」のようなファイル名になっているので、
分かりやすいファイル名に変更しておくといいです。
自分の場合は「test_whisper.ipynb」としました。(安直だな!)

NotebookのGPU設定を有効にする
次にNotebookの設定を行います。
「編集>ノートブックの設定」から
「ハードウェアアクセラレータ」の項目を「GPU」に設定します。
(作成直後は「None」(指定なし)の状態になっていると思います。)


これで、このNotebookではGPUが割り当てられて、
GPUを用いた処理を行うことが可能になります。
機械学習を行う場合はCPUのみだと処理に時間がかかることが多く、
GPUを用いていろいろやって(適当)処理を高速化するようにしています。
ローカルPC環境で行う場合はそのPCにグラフィックボードがないとできませんが、
GoogleColaboratoryでとりあえず動かすだけなら、
この設定を行えば、使用する仮想環境にGPUが割り振られるため、
GPUを使って機械学習を試すことができます。
Whisperと必要なライブラリの
インストール、アップデート
Whisperを動かすのに必要なライブラリをインストールしていきます。
「+コード」の部分をクリックして、作成されたコード入力部分に
下記の内容を記載します。

1行目がWhisperのインストール
2行目~3行目が
システムの更新と、Whisperを動かすのに必要なffmpegのインストールです。
すると、書いたコードが実行されて、上記のインストールが行われます。
ローカル環境に準備する場合はPythonのバージョンとかがいろいろ手順があるんですが
GoogleColaboratoryだと、はじめっから用意されているのを使うことができるので
これだけで出来るんですね。ありがたいなあ。
字起こしするデータのアップロード
準備はこれで出来たので、次に字起こしを行うデータを
GoogleColaboratoryにアップロードします。
動かしているのはGoogleの仮想環境ですからね。
左端っこのフォルダアイコンをクリックすると、
仮想環境上のファイルエクスプローラみたいなのが表示されます。
アップロードアイコンを選択すると、
ローカル環境のPCのファイルを、ここにアップロードすることができます。
(ファイルをここにドラッグ&ドロップするだけでもできます。)

今回字起こしには、下記のページのデータを使用しました。
Audio Samples from "Human-in-the-loop Speaker Adaptation for DNN-based Multi-speaker TTS"https://sython.org/demo/udagawa22interspeech/demo_slstts.html
アップロード時に下記のような注意メッセージが表示されると思います。
これは、
GoogleColaboratoryが一定時間経過すると、仮想環境をリセットしてしまうため
「その時にアップロードしたファイルも削除されてしまいますよ。ということです。
「OK」を押して、アップロードを実行しましょう。

Notebookの環境上に置かれたのが分かります。

Whisperの実行
では、アップロードしたファイルを使って、
実際にWhisperを実行して字起こししてみましょう。
GoogleColaboratoryにアップロードしたファイル部分を右クリックすると
下記のようなメニューが出てくるので、そこから「パスをコピー」を選択します。
すると、クリップボード上にこのファイルのパスが格納されます。

取得したファイルのパスを使って、whisperにファイルを指定して字起こしを実行します。
「+コード」をクリックして、新しくできたセル部分に
下記のような感じでコードを書いて、実行します。
「--language」が字起こしの言語設定、
「--model」が字起こしに使用する学習モデルの設定ですね。
初回実行時は学習モデルのダウンロードも実行されるため、
少し時間がかかると思います。
実行結果とファイルの出力
自分の環境で得られた結果をスクリーンショットで載せておきます。
ダウンロード時にファイル名をいじっていたり、
アップロード場所をsample_dataのフォルダにしたりしていますが、
大体同じ結果が得られるかと思います。


実行後、Notebookの仮想環境上に
Whisperの実行によって出力されたファイルが表示されます。
(表示までに時間がかかることがあります。
「ファイルアップロード」の隣にある「ファイル同期」アイコンを押すと
直ぐに表示されると思います。)
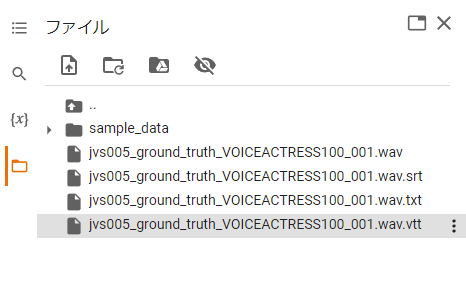
テキスト形式(txt)、動画字幕形式(vtt,srt)の
3ファイルが入力データと同名のファイル名で出力されていますね。
このファイルリストから項目を選択し、
右クリックから表示されるメニューでファイルをダウンロードすることができます。
字起こし直後のデータは、実行時の表示の通り、
若干文言が実際とは異なる場合もあるので、ダウンロードした後、
少し手直しすると、実際の動画の字幕データとしても使用できるのではないかな
と思います。
動かしてみた感想
いやー楽でしたね (笑)
持っているPCの性能で出来なかったり、
インストールするPythonのバージョンを気にしたりとかがないので
とりあえず動かしてみたいという場合はGoogleColaboratoryでやるのが
面倒がなくていいんではないでしょうか?
とはいえ、実際にこういったことをビジネス的なサービスとして実現したい場合や、
GoogleColaboratoryの提供される環境よりも性能のよいPCが必要だったり、
使用制限を取っ払って24時間動かしたいとか、そういうレベルになってくると、
やはりローカルPC上で自分で環境を整える必要が出てくるわけで、
一概に「GoogleColaboratoryだけでいいじゃん」とはならないわけですね。
このあたりは「やりたいこと」との兼ね合いになってきそうですかね。
今回はこのあたりで。
それではでは。
0 件のコメント:
コメントを投稿